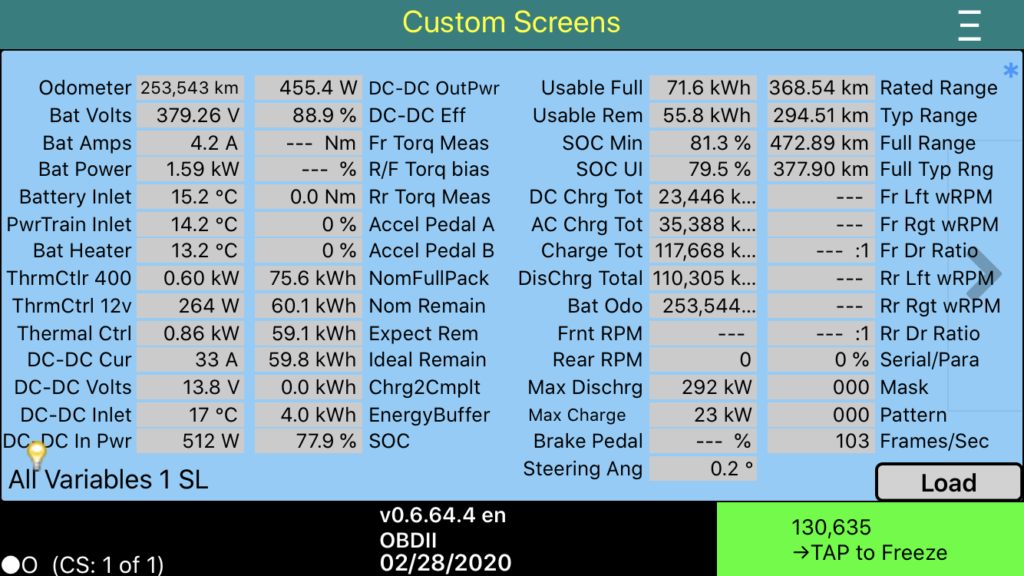
For a Ceph cluster I have two Juniper QFX5100 switches running as a Virtual Chassis.
This Virtual Chassis is currently only performing L2 forwarding, but I want to move this to a L3 setup where the QFX switches use Dynamic Routing (BGP) and thus become the gateway(s) for the Ceph servers.
This should work, but one of the things I was missing is a dedicated Management Port which uses a different routing table/instance.
Starting with JunOS 17.3R1 you can create a Management Routing Instance as described on the website of Juniper.
set system management-instance
This now creates the Routing Instance called mgmt_junos.
I try to run as much as possible IPv6-only or at least prefer IPv6 over IPv4.
I ran into the problem that configuring an IPv6 address on my em0 interface just wouldn’t work. It kept saying that the IPv6 address was Duplicate.
This is probably something which happens because both QFX switches are connected to the same Out of Band switch and causes it to receive it’s DAD over a different link. I had to disable DAD on interface em0 to make it work.
In addition I configured all DNS lookups to be performed using this routing instance.
The end result for my configuration (snippets):
system {
management-instance;
name-server {
2a00:f10:ff04:153::53 routing-instance mgmt_junos;
2a00:f10:ff04:253::53 routing-instance mgmt_junos;
93.180.70.22 routing-instance mgmt_junos;
93.180.70.30 routing-instance mgmt_junos;
}
}
interfaces {
unit 0 {
family inet {
address 172.17.5.10/24;
}
family inet6 {
address 2a00:f10:XXX:XXX::100/64
dad-disable;
}
}
}
routing-instances {
mgmt_junos {
routing-options {
rib mgmt_junos.inet6.0 {
static {
route ::/0 next-hop 2a00:f10:XXX:XXX::1;
}
}
static {
route 0.0.0.0/0 next-hop 172.17.5.1;
}
}
}
}
This now allows me to SSH to my Juniper QFX Virtual Chassis over interface em0 which uses a different routing instance/table.
Should I make a mistake in the default routing instance, for example a BGP misconfiguration, I can still SSH to my switch(es).
Or if there is a routing error (BGP issue) I can also still reach the switches.