Our house (2020) is being heated and cooled by a Stiebel Eltron WPL20AC heatpump. Being a techy I searched if there was a possibility to extract some statistics out of the heat pump and connect it to my Home Assistant.
The pictures above show the system while being installed in the summer of 2020.
ISG web
Fast forward to 2024 and after some searching I found the ISG web from Stiebel Eltron.
A device which connects to the CAN bus of the heatpump and exposes the information via a Web UI and additionally via Modbus TCP/IP (additional software required!).
I purchased a ISG web (EUR 170) and tried to connect it myself.
I thought it was a matter of connecting the Ethernet and then the CAN bus cable on the WPsystem board inside the heatpump. Turned out everything on the board was occupied and the manuals of Stiebel Eltron were not very clear.
CAN bus connection
Luckily we had a servicemen come over for some maintenance on the heatpump and I asked him to connect the ISG to the WPsystem board. He did by connecting the cables to the GREEN (CAN B) connection X1.2.
Here you can see the grey cable coming from the ISG web connected to the X1.2 connector in parallel.
ISG web UI
The ISG is now working and I can see the information in the Web UI.
Recently I was asked to assist with setting up a BGP+EVPN+VXLAN network where Juniper MX204 routers would be the gateways in the VNI and the rest of the network would consist of Spine and Leaf switches running Cumulus Linux.
The actual workload would run on Proxmox servers which would also run Frrouting. I wrote a post about this earlier.
I’ll make this a short post as you are probably reading this to find a solution to your problem, I’ll make it short and post the configuration.
Interoperability
BGP and EVPN are standardised protocols and they should work between vendors. EVPN is however still fairly new and vendors sometimes implement features differently.
I noticed this with the route-targets/communities set by FRR and JunOS for EVPN routes. These would not match and thus JunOS and FRR would not learn eachothers EVPN routes.
Solution / Configuration
In this case the solution was to set the route-target/community/vrf-target for all EVPN routes (and thus VNI) to 100:100 (something I chose).
This now resulted in JunOS and Frr learning the EVPN routes and this then also showed in the EVPN database of JunOS. The VMs in Proxmox were now able to reach the internet!
wido@juniper-mx204> show evpn database l2-domain-id 1500
Instance: evpn
VLAN DomainId MAC address Active source Timestamp IP address
1500 00:00:5e:00:01:01 05:00:00:fd:e9:00:00:05:dc:00 May 22 06:57:59 xx.124.220.3
1500 00:00:5e:00:02:01 05:00:00:fd:e9:00:00:05:dc:00 May 22 06:57:59 xx:xx:2::3
1500 46:50:13:6d:5d:bb 10.255.0.17 May 23 05:44:20
1500 74:e7:98:30:8c:e0 irb.1500 May 18 06:29:04 xx.124.220.1
xx:xx:2::1
fe80::76e7:9805:dc30:8ce0
1500 80:db:17:eb:d5:d0 10.255.0.2 May 22 06:57:59 xx.124.220.2
xx:xx:2::2
fe80::82db:1705:dceb:d5d0
1500 9a:9a:94:80:1a:3a 10.255.0.17 May 23 06:02:25
1500 ca:f0:03:fe:d6:dd 10.255.0.17 May 22 18:18:43
1500 f6:db:10:b6:5b:c4 10.255.0.17 May 23 05:58:39 xx.124.220.6
wido@juniper-mx204>
I recently upgraded my Lenovo X1 Carbon (5th gen) from Ubuntu 20.04 to 22.04 and my 4G connection stopped working.
I travel a lot and one of the great features of the Lenovo X1 Carbon is the (optional) 4G/LTE modem which I use with an additional data-sim of my provider (Vodafone NL).
After not really wanting to fix it (time constraints) I put some time in it and searching around a bit I found the solution for my problem.
It has has to do with the Sierra Wireless EM7455 modem and an updated version of ModemManager in Ubuntu 22.04. The modem is locked by default and has to be unlocked by sending a ‘magic’ combination of commands.
Now keep in mind that this solution only works if you have a Sierra Wireless EM7455 modem. You can check this with the output of the lsusb command.
Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 003 Device 002: ID 1050:0407 Yubico.com Yubikey 4/5 OTP+U2F+CCID
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 005: ID 138a:0097 Validity Sensors, Inc.
Bus 001 Device 004: ID 13d3:5682 IMC Networks SunplusIT Integrated Camera
Bus 001 Device 003: ID 8087:0a2b Intel Corp. Bluetooth wireless interface
Bus 001 Device 019: ID 1199:9079 Sierra Wireless, Inc. EM7455
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
After creating the right symlink to unlock my Modem I was able to connect to the Vodafone network again and no longer had to use my phone’s wireless hotspot!
IPv6
wido@wido-laptop:~$ sudo ip addr show dev wwan0
12: wwan0: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UNKNOWN group default qlen 1000
link/ether fa:73:bc:24:0f:24 brd ff:ff:ff:ff:ff:ff
inet 100.71.255.77/30 brd 100.71.255.79 scope global noprefixroute wwan0
valid_lft forever preferred_lft forever
wido@wido-laptop:~$
Unfortunately Vodafone still (Jan 2023) does not support IPv6 on their 4G network. It’s coming I’ve heard….
Using the routing daemon Frrouting a Proxmox cluster can also be configured to use BGP with EVPN+VXLAN for it’s routing allowing for very flexible networks.
I won’t go into all the details of Frr, BGP, EVPN and VXLAN as the internet already more then enough resources about this. I’ll get right to it.
Frrouting
After installing Proxmox (7.1) on the node I temporarily connected the node via a ad-hoc connection to the internet to be able to install Frr.
curl -s https://deb.frrouting.org/frr/keys.asc | sudo apt-key add - echo deb https://deb.frrouting.org/frr bullseye frr-7 | sudo tee -a /etc/apt/sources.list.d/frr.list apt install frr frr-pythontools
After installing Frr I configured the /etc/frr/frr.conf config file:
frr version 7.5.1
frr defaults traditional
hostname infra-72-45-36
log syslog informational
no ip forwarding
no ipv6 forwarding
service integrated-vtysh-config
!
interface enp101s0f0np0
no ipv6 nd suppress-ra
!
interface enp101s0f1np1
no ipv6 nd suppress-ra
!
interface lo
ip address 10.255.254.5/32
ipv6 address 2a05:1500:xxx:xx::5/128
!
router bgp 4200400036
bgp router-id 10.255.254.5
no bgp ebgp-requires-policy
no bgp default ipv4-unicast
no bgp network import-check
neighbor core peer-group
neighbor core remote-as external
neighbor core ebgp-multihop 255
neighbor enp101s0f0np0 interface peer-group core
neighbor enp101s0f1np1 interface peer-group core
!
address-family ipv4 unicast
redistribute connected
neighbor core activate
exit-address-family
!
address-family ipv6 unicast
redistribute connected
neighbor core activate
exit-address-family
!
address-family l2vpn evpn
neighbor core activate
advertise-all-vni
exit-address-family
!
line vty
!
In this case the host will be connecting to two Cumulus Linux routers using BGP Unnumbered.
The interfaces enp101s0f0np0 and enp101s0f1np1 are the uplinks of this node the the two routers.
/etc/network/interfaces
Now we need to make sure the /etc/network/interface file is populated with the proper information.
auto lo iface lo inet loopback
auto enp101s0f1np1 iface enp101s0f1np1 inet manual mtu 9216
auto enp101s0f0np0 iface enp101s0f0np0 inet manual mtu 9216
This makes sure the interfaces (Mellanox ConnectX-5 2x25Gb SFP28) interfaces are online and running with an MTUof 9216.
The MTU of 9216 is needed so I can transport traffic with an MTU of 9000 within my VXLAN packets. VXLAN has an overhead of 50 bytes. So to transport an Ethernet packet of 1500 bytes you need to make sure you have at least an MTU of 1550 on your VXLAN underlay network.
VXLAN bridges
I now created a bunch of devices in the interfaces file:
auto vxlan201
iface vxlan201 inet static
mtu 1500
pre-up ip link add vxlan201 type vxlan id 201 dstport 4789 local 10.255.254.5 nolearning
up ip link set vxlan201 up
down ip link set vxlan201 down
post-down ip link del vxlan201
auto vmbr201
iface vmbr201 inet manual
bridge_ports vxlan201
bridge-stp off
bridge-fd 0
auto vxlan202
iface vxlan202 inet static
mtu 1500
pre-up ip link add vxlan202 type vxlan id 202 dstport 4789 local 10.255.254.5 nolearning
up ip link set vxlan202 up
down ip link set vxlan202 down
post-down ip link del vxlan202
auto vmbr202
iface vmbr202 inet manual
address 192.168.202.36/24
bridge_ports vxlan202
bridge-stp off
bridge-fd 0
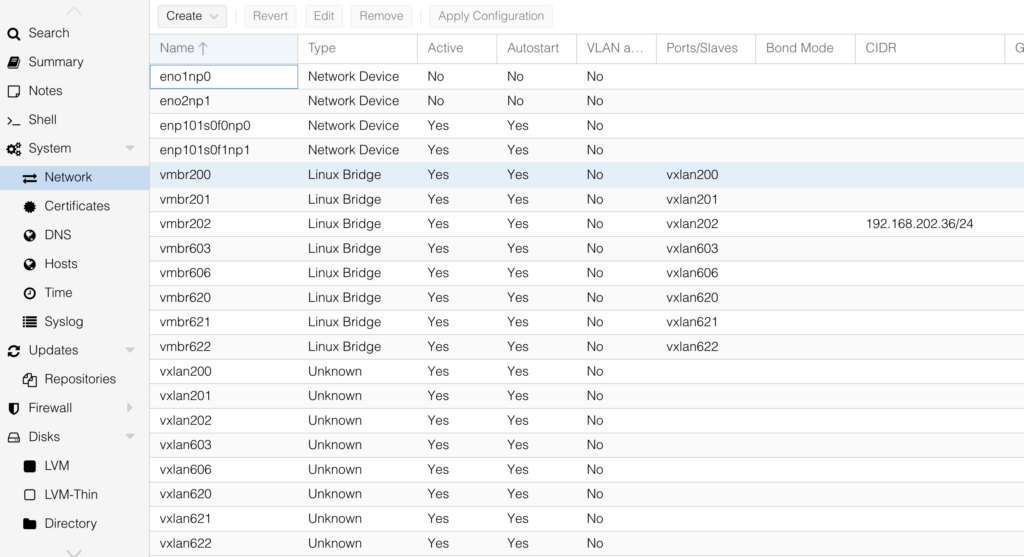
I created vmbr201 and vmbr202 which correspond to VNI 201 and 202 on the network. These can now be used with Proxmox to connect VMs to.
The IP-Address (10.255.254.5) set at the local argument of the ip command is the IP-address connected to the loopback interface and advertised using BGP.
This will be the address used for the VTEP in EVPN/VXLAN communication.
In reality however I have much more bridges
vmbr200
vmbr201
vmbr202
vmbr601
vmbr602
vmbr603
vmbr604
Overview of interfaces in Proxmox
Proxmox cluster network
To be able to create a cluster with Proxmox you need a Layer2 network between the hosts where corosync can be used for cluster communication.
In this case I’m using vmbr202 which has IP-address 192.168.202.36/24 on this node. Other nodes in the cluster have a IPv4 address in the same network and allows them to communicate with the others.
Apache CloudStack does not have a build-in mechanism to rate-limit failed authentication attemps on the API. This potentially allows an attacker to brute-force credentials and gain access.
The api.allowed.source.cidr.list configuration option in CloudStack can be used to globally or on an account level limit the source IPs where the API allows requests from. This is always good to do (if possible), but it does not cover every use-case.
Sometimes you just want to keep malicious traffic outside the door and fail2ban can help there.
Nginx proxy in front of CloudStack
A common use-case is that the Management server of Apache CloudStack is not directly connected to the network, but placed behind a reverse proxy like Nginx or something similar.
This proxy can then also handle SSL termination.
In this example we’re using Nginx as a proxy.
fail2ban
Using fail2ban we can scan the access logs of Nginx and block IP addresses who are abusing our API. In this case we filter on two HTTP status codes:
401
531
This results in that we create the following files:
When we talk about IP protocols and IPv6 in this particular case we think about routing over the internet. But what many do not know is that IPv6 is already playing a major role in all kinds of systems.
In this post I’m not going to explain IPv6 in detail, for many things I’ll link to external pages.
Ad-Hoc networking using Link-Local
IPv6 has a great feature where each host on a network will generate a Link Local Address (LL) which is mandatory according to the protocol.
The great thing about LL is that it allows hosts to establish communication without the need of DHCP or anything else. Just plug in a host on a Layer 2 Ethernet network and they can start communicating right away.
fe80::5054:ff:fe98:aaee is an example of a IPv6 LL address and using this address it can search for (via multicast) and communicate with other hosts in the network.
CCS is a standard for (fast charging) electric vehicles. Some years ago I stumbled upon multiple documents showing that CCS would be using a combination of PLC, IPv6, TCP/IP, UDP, HTTP, TLS and many other very common protocols for communication.
Using PowerLine Communication (PLC) the vehicle and charger will establish a Layer 2 Ethernet network over which they will communicate using IPv6 LL.
I was not able to find the exact details of the IPv6 part of the CCS standard, but it is very interesting to see that IPv6 is being used for something like charging electric vehicles.
Kudos to the people behind CCS and for using IPv6 for this!
In my opinion it’s a no-brainer to use IPv6 for such functionality as the LL addressing allow you to create networks very quickly and in a reliable manner.
You can also use a very well documented protocol and the many tools for IPv6.
It’s been almost a year that I’ve been living in my new house and proud father of a son.
Almost every parent wants to watch their little on through a camera to see them sleeping in their bed.
There are many, many, many baby monitors on the market but in my experience they are allcrap. Our house is build with a lot of concrete and none of them was able to penetrate the walls in our house and thus have a reliable video connection.
I also tried some IP/WiFi based baby monitors from for example Foscam, but these are all cheap Chinese cameras and didn’t work either. Crashing iPad apps, sending random (UDP) packets to China, half-baked UIs, etc, etc. They were all very low quality.
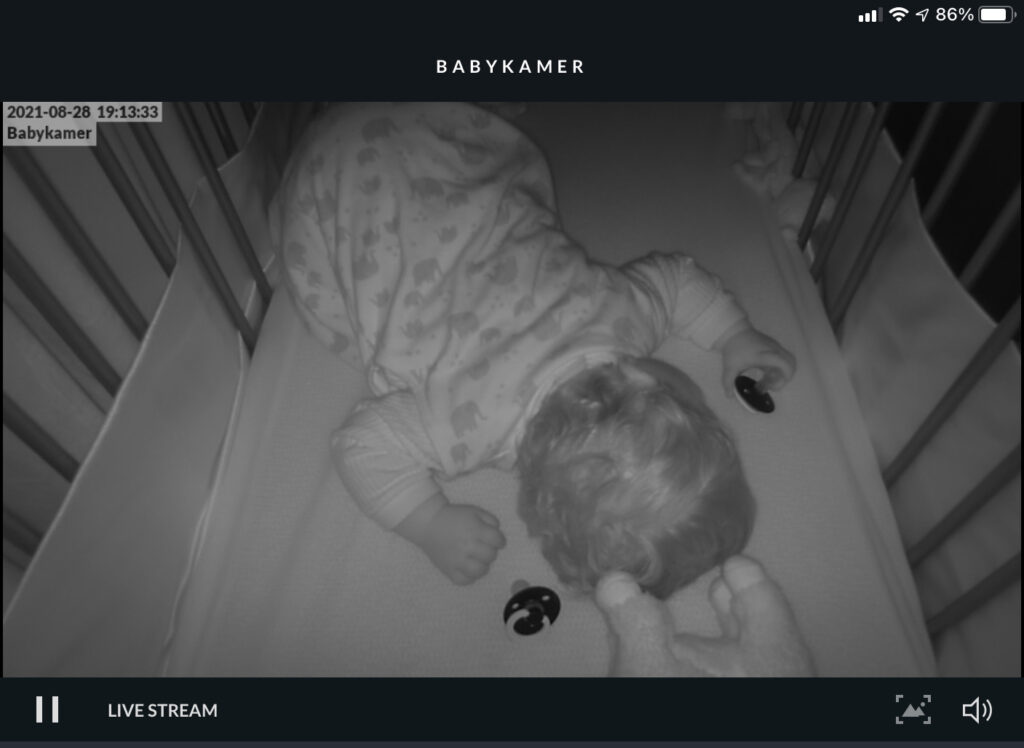
After a lot of frustrating I bought a Unifi Video G3 (UVC-G3-BULLET) camera and mounted it on the bed of my son.
Unifi Video G3 camera mounted on baby bed
I am using multiple Unifi video cameras around my house using Unifi Video, so for me it was just a matter of adding an additional camera to my Unifi system.
Video camera in Unifi Video
RTMP + HLS with Nginx
I also experimented with building a video stream using RTMP, ffmpeg and HLS with Nginx.
The Unifi cameras can export a RTSP stream which you can set up to live stream with Nginx. I tried this and it works for me, but with a delay of ~20s I thought it was not usable on my use-case.
It does however allow for a very easy way of building your own webcam!
In the past years I’ve said goodbye to hardware RAID controllers and mainly relied on software solutions like mdadm, LVM, Ceph and ZFS(-on-Linux) for keeping data safe.
At PCextreme we use hypervisors with local NVMe storage running in Linux’s mdadm software RAID-10. This works great! But I wasn’t satisfied with the performance for a few reasons:
It is expensive on the CPUs (Dual AMD Epyc 48-core)
It’s not super fast
We mainly use the Samsumg PM983 (1.92TB) devices and I started to look around if there is a hardware solution which could offload the RAID computation to a dedicated SoC so it wouldn’t eat up our CPU cycles.
After searching I found the Broadcom SAS3916 chip which is on the MegaRAID 9516-16i controller from Broadcom. This chipset supports NVMe devices in various RAID modes.
I wanted to benchmark Linux’s software RAID against the Broadcom controller to see if it would be faster and save us the expensive CPU cycles.
With mdadm we also looked into RAID-5/6 to have more usable space. We however found out that this eats up so many CPU cycles that it wasn’t feasible to use in production for our purposes.
Benchmarking setup
Ubuntu Linux 18.04 with kernel 5.3
SuperMicro 1114S-WN10RT
AMD Epyc 7302P 16-core CPU
128GB Memory
4x Samsung PM983 1.92TB
Broadcom MegaRAID 9516-i
Benchmarking will be done using fio and the main elements we are looking for:
In addition you can download my Open Office spreadsheet I used to generate the graphs and process the data.
Graphs
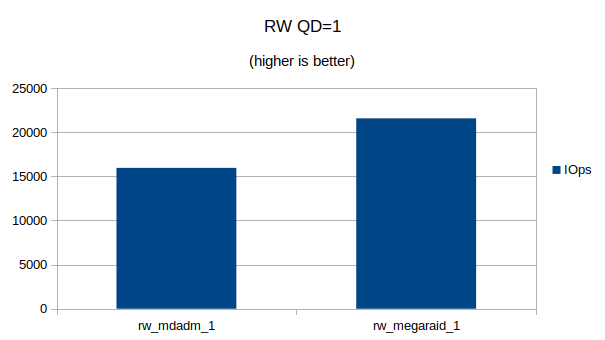
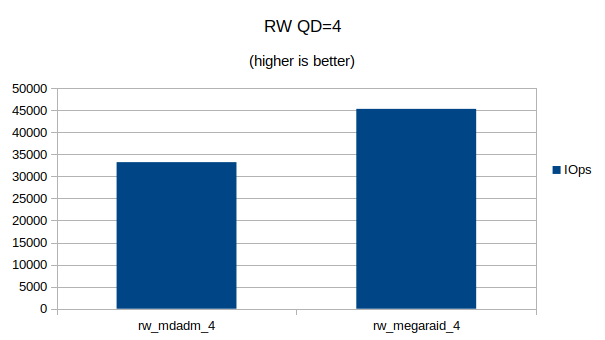
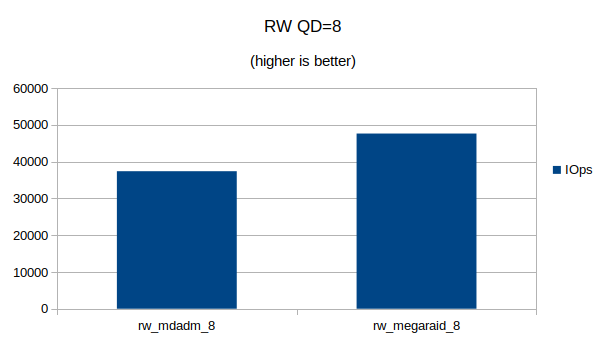
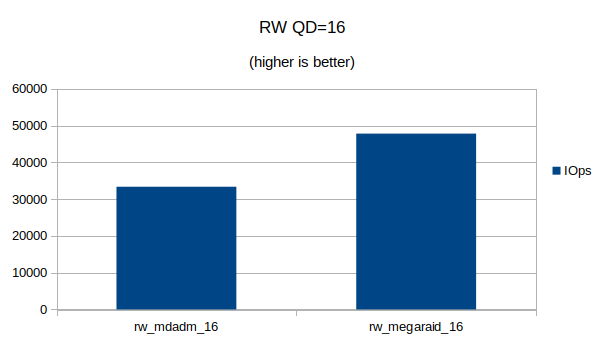
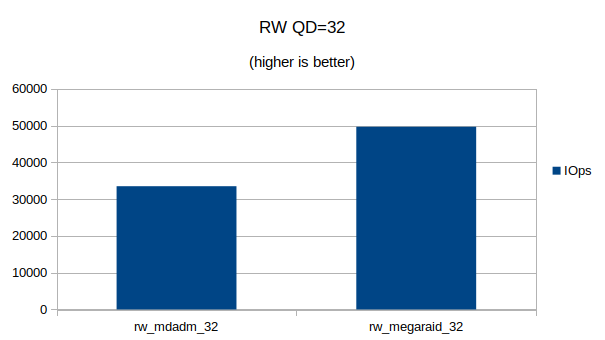
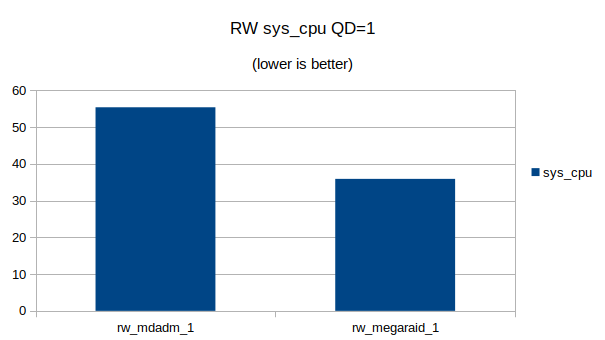
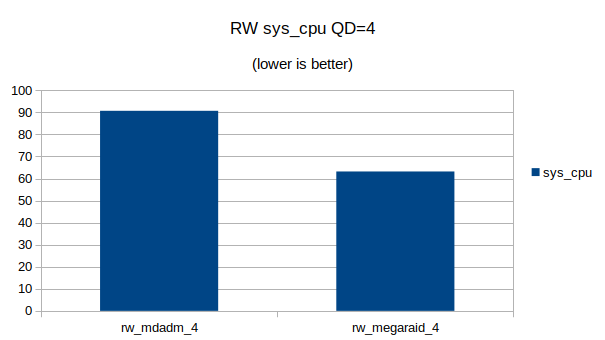
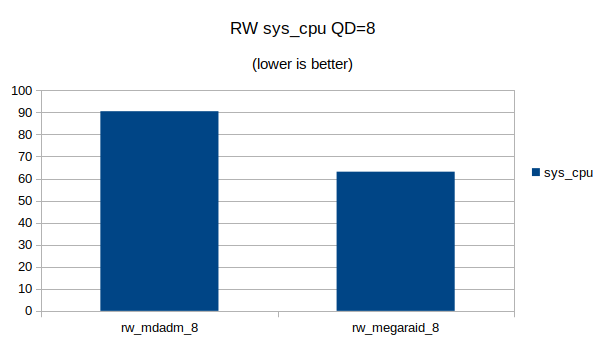
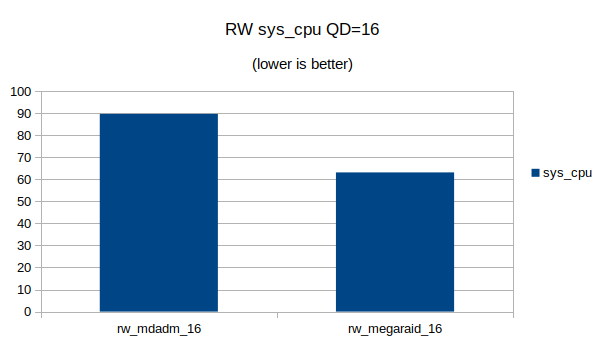
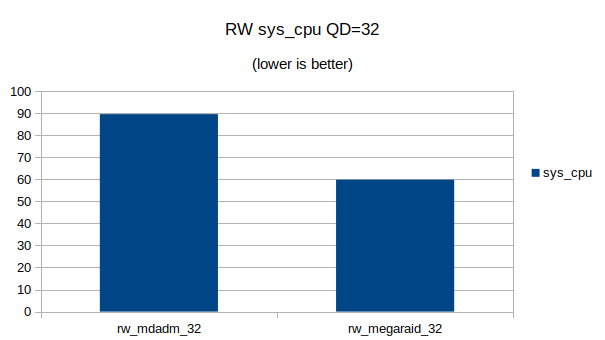
Some graphs with the results of the IOps and CPU utilization.
At QD 16~32 we seem to have found the upper limit of what the 4 NVMe devices are capable of. Going from QD 16 to 32 does not make a significant difference.At QD32 we can still see that the MegaRAID controller uses a lot less CPU cycles then Linux’s software RAID
While replacing my router at home by a MikroTik CCR1036-8G-2S+ router I also wanted to uplink my Ubiquity switch using a Multimode (OM3) connection.
Is fiber really needed? Not really, but it saved me an additional RJ45 port on my switch which allows me to connect more.
Link up, down, up, down
The link between my MikroTik router and Unifi switch kept going up and down. In the logs on my MikroTik and Unifi switch I saw:
<14> May 26 19:19:07 SwitchPatchkast DOT1S[dot1s_task]: dot1s_sm.c(314) 454679 %% Port (26) inst(0) role changing from ROLE_DESIGNATED to ROLE_DISABLED <14> May 26 19:19:07 SwitchPatchkast DOT1S[dot1s_task]: dot1s_sm.c(314) 454677 %% Port (26) inst(0) role changing from ROLE_DISABLED to ROLE_DESIGNATED <13> May 26 19:19:07 SwitchPatchkast TRAPMGR[trapTask]: traputil.c(743) 454676 %% Link Up: 0/26 <14> May 26 19:18:58 SwitchPatchkast DOT1S[dot1s_task]: dot1s_sm.c(314) 454668 %% Port (26) inst(0) role changing from ROLE_DESIGNATED to ROLE_DISABLED <13> May 26 19:18:58 SwitchPatchkast TRAPMGR[trapTask]: traputil.c(743) 454667 %% Link Down: 0/26
19:25:12 interface,info sfp-sfpplus1 link up (speed 1G, full duplex)
19:25:20 interface,info sfp-sfpplus1 link down
19:25:21 interface,info sfp-sfpplus1 link up (speed 1G, full duplex)
19:25:29 interface,info sfp-sfpplus1 link down
19:25:30 interface,info sfp-sfpplus1 link up (speed 1G, full duplex)
19:28:48 interface,info sfp-sfpplus1 link down
I am using optics from FlexOptix which I programmed to MikroTik and Ubiquity using their programmer. (We have those at work).
Auto negotiation
After trying many things it turned out that turning off Auto Negotation on both the switch and the router resolved the issue.
On the switch I turned it off via the UI of the Unifi Controller and forced it to 1000 FDX.
On the router I turned it off using the MikroTik CLI: